At present, China's body electronic voice control is mainly concentrated on the application of car navigation systems, and the application of voice recognition technology in body electronics has not been fully exerted. This paper presents for the first time a design scheme of a non-specific human car audio voice control system composed of a dedicated voice processing chip UniSpeech-SDA80D51 as the core, and realizes the development of the system prototype.
1 Car audio voice control system
The system is composed of modules such as voice collection, voice recognition, control drive and car audio. The main functions completed by the system are: the voice collection module is used to collect the voice command signal issued by the driver, and the A / D conversion of the signal is realized by the voice recognition module. And perform voice recognition processing on the converted digital signal, and finally output the coded entry corresponding to the voice command. The control module logically analyzes and processes the received coded entry and generates a corresponding control signal to drive the car audio action instead Driver's manual operation.
1.1 Voice recognition module
The speech recognition module is mainly composed of UniSpeech-SDA80D51 chip and peripheral circuits.
SDA80D51 is a newly-introduced high-integration SoC chip specially designed for speech recognition and speech processing applications by German Infineon. Its basic structure is shown in Figure 1.
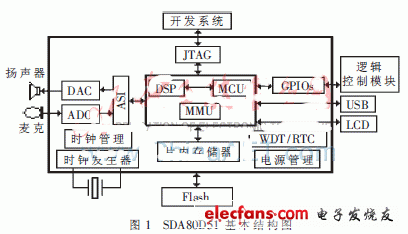
As can be seen from Figure 1, SDA80D51 integrates components such as direct dual-access fast SRAM, 2-channel ADC and 2-channel DAC, multiple communication interfaces and general GPIO. The SDA80D51 working mode uses M8051 as the main control chip, which mainly completes the system configuration and the control of SPI, PWM, I2C, GPIO and other interfaces, as well as the transmission of voice data; DSP core OAK is a coprocessor that completes voice recognition algorithms and voice codec algorithms Wait for voice processing.
The unspecified person's voice signal is input by the directional pickup, undergoes A / D conversion through the internal data collection module of SDA80D51, and then undergoes the preprocessing of the recognition program, endpoint detection, feature parameter extraction, template matching and other processing, selects the closest in the recognition vocabulary The serial number of the entry is used as the recognition result, and the recognition result is output through the GPIO port.
1.2 Control drive module
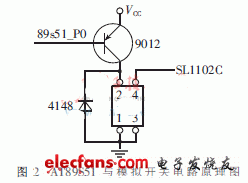
The control and driving module is composed of MCU, analog switch and peripheral circuit. The module is mainly used to receive the speech recognition result, perform logic analysis and processing on the coded entry signal, and generate the corresponding function control signal to drive the sound action through the analog switch circuit. Among them, MCU selects AT89S51 product from American ATMEL company, which combines the characteristics of AT89S51 output I / O signal voltage and the characteristics of the SL1102C1 audio control panel resistive shunt keyboard circuit, and it is determined to use the relay to simulate the closing and opening actions of the SL1102C1 control panel keys. The schematic diagram of AT89S51 and relay analog switch circuit is shown in Figure 2.
1.3 Audio module
This design is based on SL1102C1 car audio. SL1102C1 is a car audio specially designed for mid-range cars, with MP3 playback, radio and time display functions. Currently, it is widely used in JAC Tongyue cars. The SL1102C1 front panel has a total of 15 buttons such as power on / off, mute, sound effects, play / pause, and a coding switch for adjusting the volume.
The front panel keying of SL1102C1 is divided voltage identification mode. The keys include two actions: short press and long press. The output voltage of AT89S51 is TTL level, direct drive audio is easy to cause key code misidentification, resulting in system misoperation, so this article uses the circuit shown in Figure 2, to solve the above problems well. When the AT89S51 receives the voice coded signal, it will immediately perform logic analysis and output the corresponding control signal to drive the relay to simulate the key press action. The short press and long press functions of the key are realized by software.
The analog switch circuit is also suitable for the code switch on the front panel of the SL1102C1. The code switch has a volume adjustment function. When the switch knob is rotated, the corresponding pulse signal is output from the upper terminal of the switch. When the MCU receives the voice command signal to operate the coding switch, the drive terminal outputs a pulse signal to simulate the function of the switch knob.
2 System software design
The system software includes a non-specific person voice recognition module and a logic control module.
2.1 Non-specific person speech recognition module
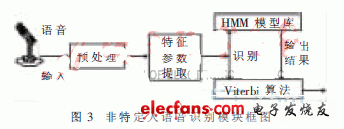
The non-specific person speech recognition module is based on a hidden Markov model algorithm. The HMM algorithm builds a statistical model speech library that recognizes vocabulary entries by performing statistics on a large amount of speech data, and then extracts features from the speech to be recognized, matches the model library, and obtains the recognition result by comparing the matching scores. Output. The non-specific person speech recognition module is mainly composed of signal preprocessing, feature parameter extraction, model matching and Viterbi algorithm. The block diagram of the module is shown in Figure 3.
2.1.1 Signal preprocessing
The signal preprocessing part mainly completes the sampling and analog / digital conversion functions of the input voice signal. A / D conversion is realized by SDA80D51 embedded 12-bit A / D converter, and the sampling frequency is fixed at 8 kHz.
2.1.2 Feature parameter extraction
Feature parameter extraction is based on speech frames, and special features are extracted using sub-frames. The voice signal is overlapped and framed first, and the previous frame and the next frame overlap by half (the frame signal overlap is to reflect the correlation between the two adjacent frames of data), the frame length is 25 ms, and a voice feature is extracted once for each frame .
The MFCC parameter belongs to the perceptual frequency-domain cepstrum parameter and reflects the characteristics of the short-term amplitude spectrum of the speech signal. The specific calculation and extraction process of p-dimensional MFCC parameters is as follows:
(1) Use DFFT to calculate the linear spectrum for each frame s (n: m), and calculate the square of the spectrum modulus as the power spectrum;
(2) The power spectrum gets D parameters X (i) through the Mel filter bank, D is the number of triangle filters in the Mel filter bank;
(3) Perform logarithmic operation and discrete cosine transform on X (i). The calculation formula of cosine transform is as follows:
Y (i) in the formula is the output of the log energy of the ith Mel filter, i = 1,2, ..., D.
Sport Bluetooth Earbuds /Wireless Earbuds/Bluetooth Earbuds
Great Conversation,high quality, hands-free phone conversation even on the street or inside shopping mall.
Charging Time:about 2 hours
Items photo as below:

Sport Bluetooth Earbuds
Sport Bluetooth Earbuds,Waterproof Headphones,Running Headphones,Sports Headphones
Shenzhen Greater Industry Co., Ltd. , https://www.szgreater.net